Penny Xu
PyTorch Autograd Computation Graph
2019-08-30
PyTorch autograd
Thank goodness for automatic differentiation. If you have ever written a backwards function in order to calculate the gradients in a multilayered network, you would know that it is not fun...especially getting the tensor dimensions correct. PyTorch Autograd really takes the frustration and pain away from the endless tensor reshapes, tensor transposes, and other tensor operations written just to compute the gradient. How does PyTorch do it?
Let's say that the four lines below are written in PyTorch, where and are the input Tensors, , , are weights, and represents the loss.
If you have used PyTorch before, you probably know that during training, we would call backward() on the in order to calculate the gradients of the trainable parameters (weights and biases) in respect to . Then we would be able to update the parameters by taking a "step" towards the negative gradient direction. Well, have you wondered how PyTorch is able to keep track of everything? From computations to gradients? The answer is Computation Graph.
Computation Graph
The graph below encodes a complete history of computation for the four lines of code above. You can see that the Tensors and the operations (functions) made between them build up an acyclic graph.
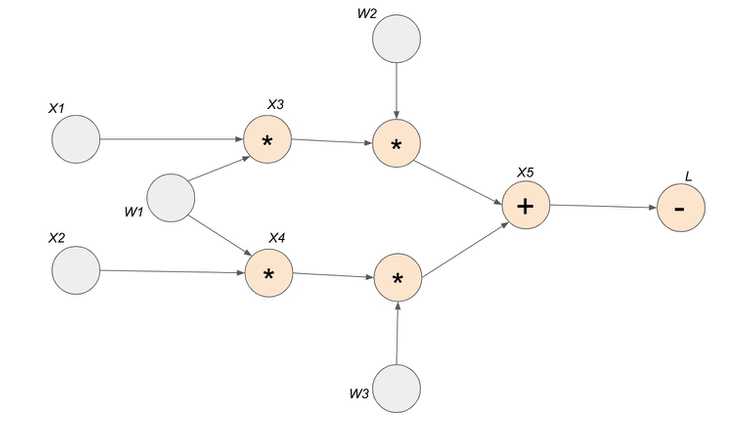
- nodes represent functions
- incoming edges represent function inputs
- outgoing edges represent function outputs
To be more specific, each node is actually a grad_fn attribute of a Tensor. For example, in our example above, the grad_fn attribute of Tensor is addition. This means that Tensor is created through the addition operator. You can see that all the orange nodes in the example computation graph is indicated by a grad_fn operator. All the grey nodes do not have an operator because they are Tensors defined by the user, so grad_fn of those Tensors is set to None.
PyTorch is Dynamic!
Computation graph is created on the fly. This means that as operations are performed on the input tensors that has autograd turned on, requires_grad = True , new nodes are added to the graph incrementally. Below demonstrates the step by step creation of the computation graph.

Backwards Propagation
Calling backward() and calculating the gradients destroys the computation graph! (By default). Make sure to use retain_variables = True if you want to do the backward on some part of the graph twice.
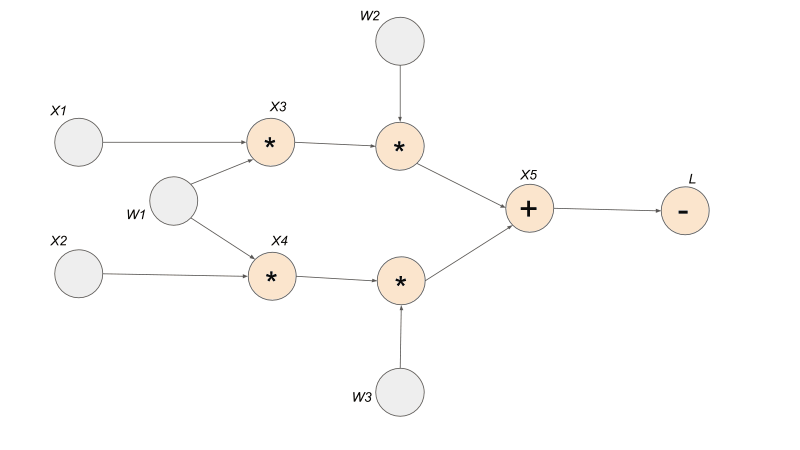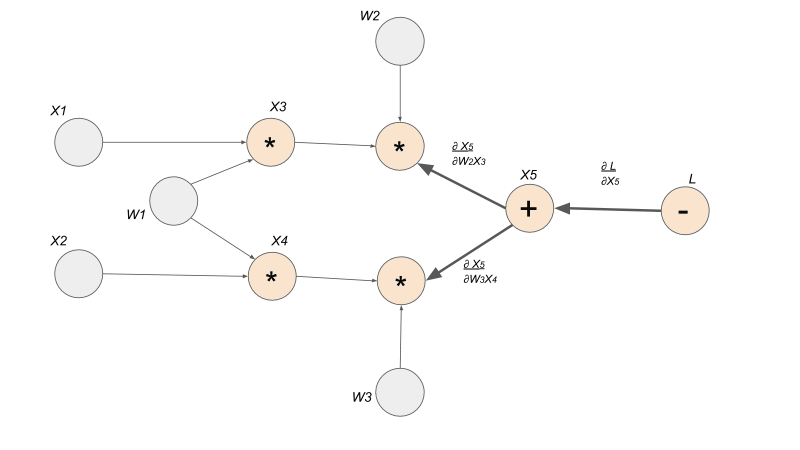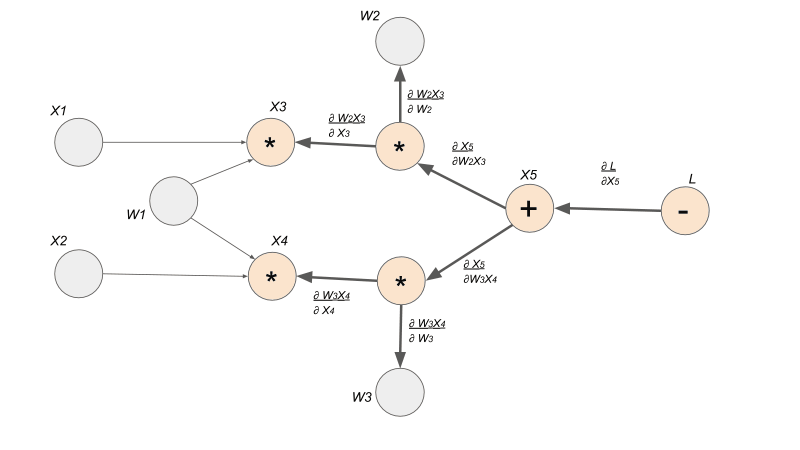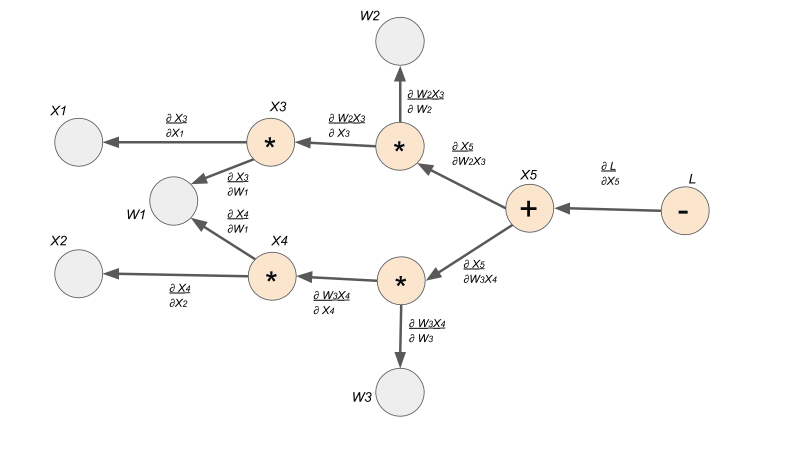
- Each edge is the gradient from one node to another
- Calling the
backward()function on one Tensor triggers thebackward()function in every Tensor that came before
Gradients
Now that we have our computation graph with the edges representing the local gradients, we can finally see how to find let's say . Finding the derivative is super easy with this gradient graph because it is simply a path finding problem. To solve for , we find the path between node and node , and we multiply the edges along the path to compute the derivative. If there are multiple paths, we would add the products from each path.
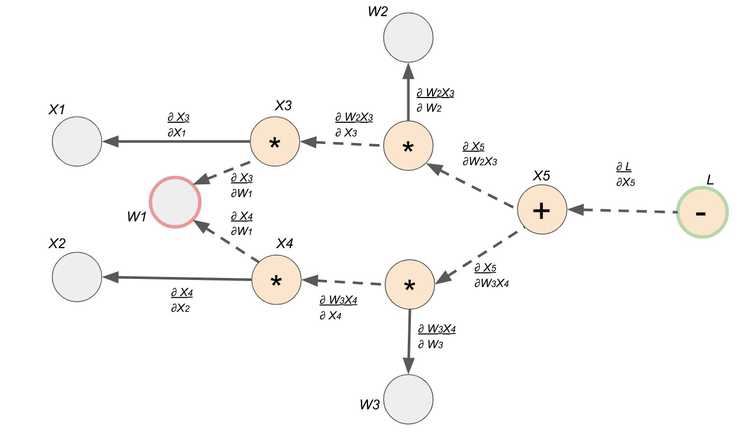
Double Check
Let's define the inputs and the weights and see if we get the same results for from the compute graph verses the magic of PyTorch autograd. Let's define the user inputs below:
, , , ,
Same computation from above:
Using equation derived from compute gradient graph:
Using PyTorch:
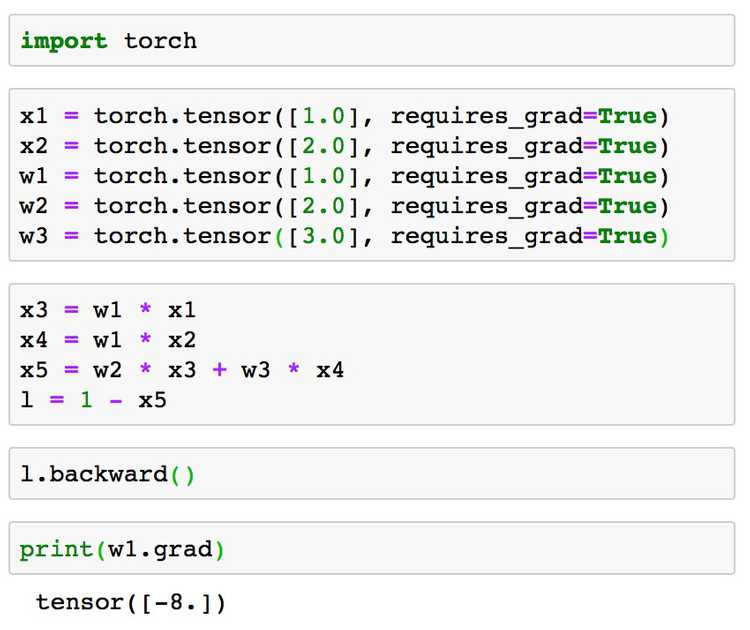
Yay! They match!