Penny Xu
Probabilistic Classifier
2019-06-12
Let's talk about classifying things with probability. Probabilistic classifiers and, in particular, the Bayesian classifier, are among the most popular classifiers used in machine learning and increasingly in many applications. These classifiers are derived from a generative probability model, where Bayes rule is used to estimate the conditional probability and then assumptions are made on the model in order to decompose this probability.
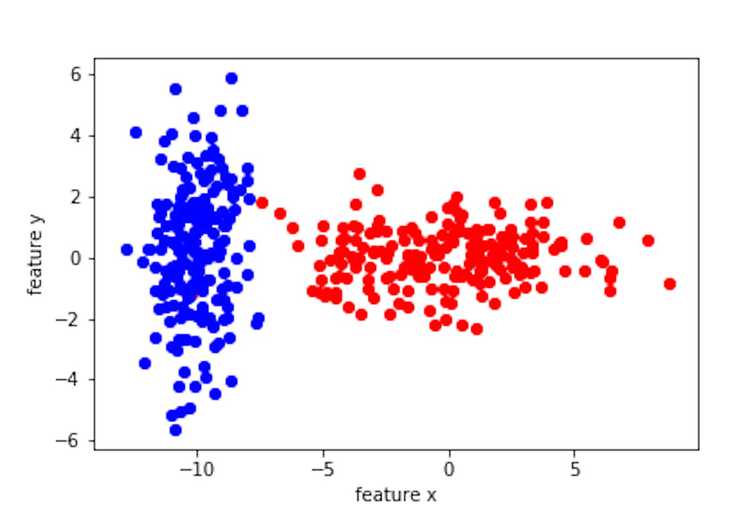
Let's say we have a two dimensional feature space, with feature vectors [x,y]. We also have the training set that is labeled. The label consists of two classes, blue and red.
Here is your task: I give you a feature vector, can you tell me which class this feature vector belongs to? I also want to know the decision boundary you used to determine the class. Is this a simple task?
In other words, would you classify the grey point below as class blue or class red?
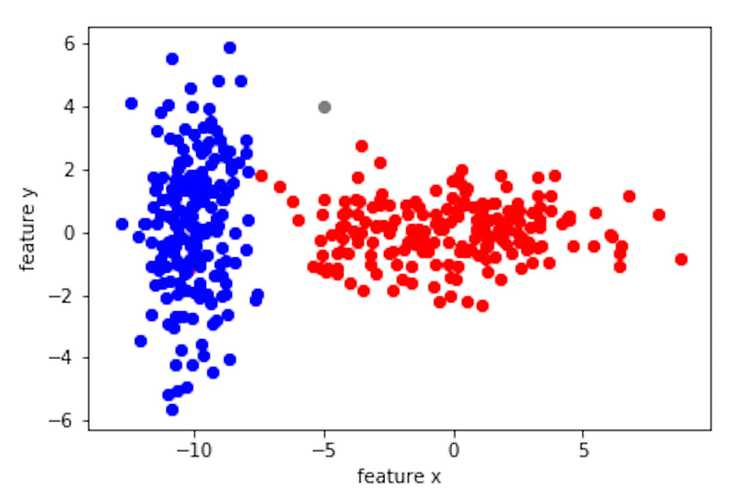
In this post, you are going to learn:
- Bayesian classifiers - what assumptions are made?
- Discriminant function - how to calculate the decision boundary?
- Linear vs quatric decision boundary - what is the difference?
Bayesian classifiers
I asked a friend who knows nothing about classifiers to tell me which class the grey point belongs to. He said it looks like it belongs to class red due to how each class "centers" and the "spread." Then he said he basically compares the standard deviations. Little did he know, what he described is exactly the intuition behind the Bayesian classifier.
Bayesian classification is a form of probabilistic classification. Intuitively, when determining a line that separates the two classes, we look at the distribution of each class. What my friend intuitively focused on was the "center" or the mean and the "spread" or the standard deviation of the distribution. Another factor can be the prior of each class. For example, if there are more blue class to begin with, then we can think that blue class is more probable and the line would shift away from the blue class. Ok, now let's put these ideas into a more mathematically rigorous form.
Giving a feature vector , we want to find the most probable class. Given classes , if , then belongs to class , and the other way around. Notice that this is a two class problem, but it can be generalized easily with multiple classes. So the question is how do we find ?
Bayes rule
Bayes rule tells me that if I want to estimate , then I need to know and . is the conditional pdf or the distribution of possible features when they belong to . It can be estimated from the training data. is the prior, which is known. For example, if we had equal number of blue and red classes in our training data, then the prior for each class would be 0.5. So this means that we will know if we can estimate .
Estimating the distribution
In order to estimate , we need to make some assumptions about the distribution of the data. This is where it gets "hand-wavy." Honestly, life would be so easy if we knew the distribution where the data is sampled from. Is the distribution uniform? binomial? poisson? normal? maybe exponential? The thing is, we don't know, so we will have to look at the data and make a reasonable assumption.
If you don't know, assume is Gaussian or normal.
k-dimension Gaussian pdf:
- is the mean of class
- is the covariant matrix of with size k x k defined by
- both of these parameters can be found from the training data
Discriminant function
Our original question: is the probability of being in less or greater than in ? At this point, we know how to get since we know both and , same applies for .
-
?
-
? (Bayes rule)
-
?
The question above partitions the feature space into two. One is when the probability of being in is greater than and the other is when the probability of is greater than . So where is the boundary that separates the two? This leads us into the discriminant function.
The line that separate the two spaces is exactly where or where .
Now let's say , called the discriminant function, where is a monotonically increasing function. Solving will give us the decision surface or line in some cases.
Now let's write out the discriminant function in it's full form, where is the natural log, which is monotonically increasing, in order to give a nice expression since the comes from the Gaussian distribution, which has the exponential term:
Great! We now know and the same can be said for , then we can find the decision boundary with !
Decision boundary
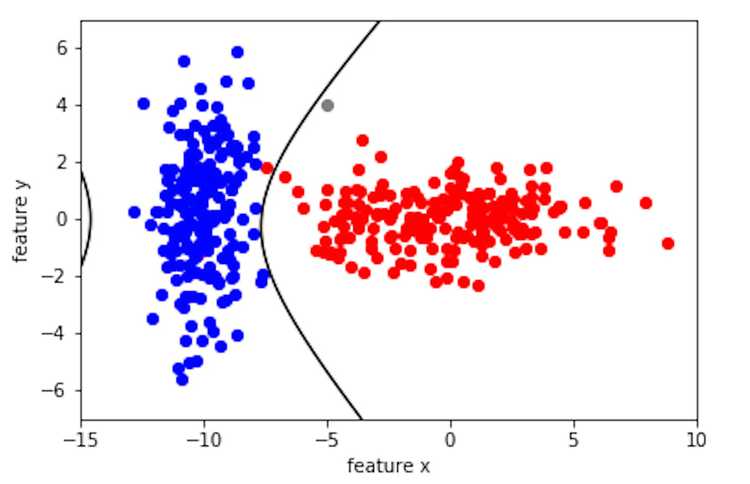
Let's get some intuition about the decision boundary. Since is a function of , a Gaussian, so is actually the intersection of two Gaussian distributions. The equation of the intersection between two Gaussians can be a circle, ellipse, parabola, hyperbola ... or an equation of polynomial of degree 2 equals zero. In other words, it is a quatric. Below is what we get when we solve the decision boundary. Notice the black decision boundary is a quatric.
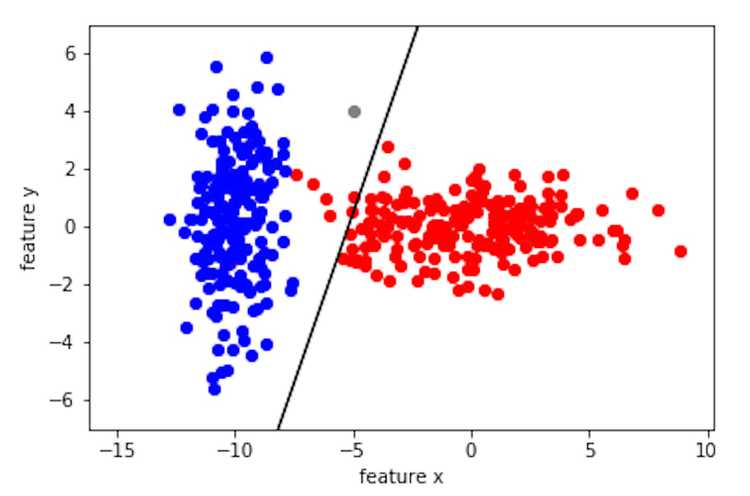
What if we want the boundary to be a line? In other words, a linear classifier. Well, a line is just a degeneration of a second order polynomial. The second order term as well as the constant of disappears when = . This means that if we assume the distribution of each class is Gaussian with the same covariance matrix, then we have a linear classifier! The discriminant function simplifies significantly into a linear equation:
Below is what we get when we solve the decision boundary in the linear case using only the covariance of the red class.
Conclusion
The Bayesian classifier is a probabilistic classifier where the decision boundary is determined by the intersection of two distributions. The quality of this classifier greatly depends on the assumptions that we make, such as the type of distribution (most commonly Gaussian), the type of covariance matrix (if they are the same for all classes), and the priors (was my training data randomly sampled). As you can see from the quatric decision boundary vs. the linear boundary, the quatric classifies the grey point as class red while the linear classifies it as class blue. So when we make these assumptions, we need to ask our selves if the tradeoff in complexity is worth it since these assumptions influences the results of the classifier. However, even with these simplified probabilistic assumptions, Bayesian classifier work remarkably well in practice. I believe the reason Bayesian classifier does well in applications is that it is simple and intuitive, as shown by my friend's intuition, where the decision boundary is simply an equation that combines the means, covariances, and the priors of the two classes!